
A salient feature representation can greatly improve the performance of a Deep Neural Network (DNN). In previous state-of-the-art work for computer vision tasks, we use pre-trained ImageNet base models for initializing network weights. As a result, we can extract significantly better features, which can then be transferred to different tasks such as object detection, semantic segmentation, human pose estimation, etc. Although, this plays a key role in improving the performance in various computer vision applications, the ImageNet pre-train process is supervised learning. Human and animal visual systems do not require careful manual annotation to learn, and instead take advantage of the nearly infinite amount of unlabeled data in their surrounding environments. Pathak et al. [1] study how to use unlabeled data to obtain a representation of the features through an unsupervised feature learning approach inspired by the human visual system for the task of object foreground versus background segmentation.
The proposed method is motivated by human vision studies, where infants and newly sighted congenitally blind people tend to oversegment static objects, but can group things properly when they move. Experiments done on humans recovering from blindness show that shortly after gaining sight, they are better able to name objects that tend to be seen in motion compared to objects that tend to be seen at rest. The work presented in this paper is related to unsupervised learning by generating images, self-supervision via pretext tasks, and learning from motion and action. The authors propose to train Convolutional Neural Networks (CNN) for the task of object foreground versus background segmentation, using unsupervised motion segmentation to provide ‘pseudo ground truth’. In the figure below we see that a strong, high-level feature representation is learned by training CNNs to group pixels in static images into objects without any class labels. A segmentation mask is generated by using optical flow to group pixels into a single object based on the ones that move in the same direction (motion information).

The generated segmentation masks are used as targets to task a CNN with predicting these masks from single, static frames without any motion information. To enable comparisons to prior work on unsupervised feature learning, they use AlexNet for their CNN architecture. Also, they use images and annotations from the training/validation set of the COCO dataset, discarding the class labels and only using the segmentations. An overview of their approach is shown in the figure below, where they use motion information to segment objects in videos without any supervision. Then, they train a CNN to predict these segmentations from static frames, i.e. without any motion information. Here, the first column is the original video frame, the second column is the mask and the third column is the output of the CNN. Their unsupervised motion segmentation algorithm is able to highlight the moving object even in potentially cluttered scenes, but is often noisy, and sometimes fails (last two rows). Nevertheless, the authors show that the CNN can still learn from this noisy data and produce significantly better and smoother segmentations.

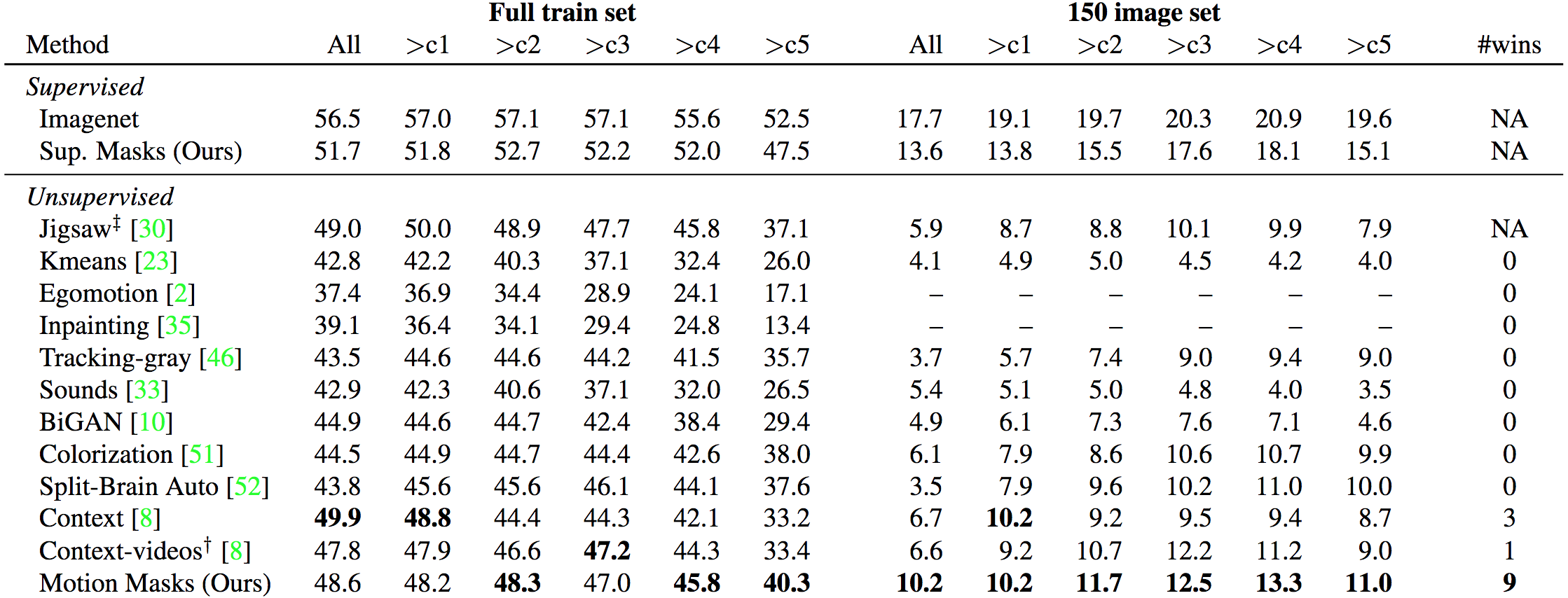
Following recent work on unsupervised learning, the authors also evaluated their learned representations by performing experiments on the task of object detection. They tested on the PASCAL Visual Objects Classes (VOC) 2007 dataset using Fast R-CNN and compared their unsupervised motion segmentation algorithm with some of the state-of-the-art methods~(see table below). It can be seen that there is a noticeable difference between supervised learning and unsupervised learning methods. However, the experimental results show that their unsupervised motion segmentation method achieves the best performance in the majority of settings, in comparison to other unsupervised methods. The learned representations are transferred to other recognition tasks to show generalization across tasks such as image classification and semantic segmentation. They experimented with image classification on PASCAL VOC 2007 (object categories) and Stanford 40 Actions (action labels). Lastly, they use fully-connected CNNs for semantic segmentation on the PASCAL VOC 2011.
One limitation is that their approach sometimes fails to segment the object in noisy data (such as cluttered scenes). Another limitation of this approach is that it often fails on videos in the wild. This is because the assumption of there being a single moving object in the video is not satisfied, especially in long videos made up of multiple shots showing different objects. A future line of work would be to explore how the single-frame output from the CNN and the noisy motion information extracted from videos can be combined to generate a better pseudo ground truth.
References
[1] Deepak Pathak, Ross Girshick, Piotr Dollár, Trevor Darrell and Bharath Hariharan. Learning Features by Watching Objects Move. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.